Understanding the Core Components of AI Coding Agents
Originally published on Ahead of AI by Sebastian Raschka
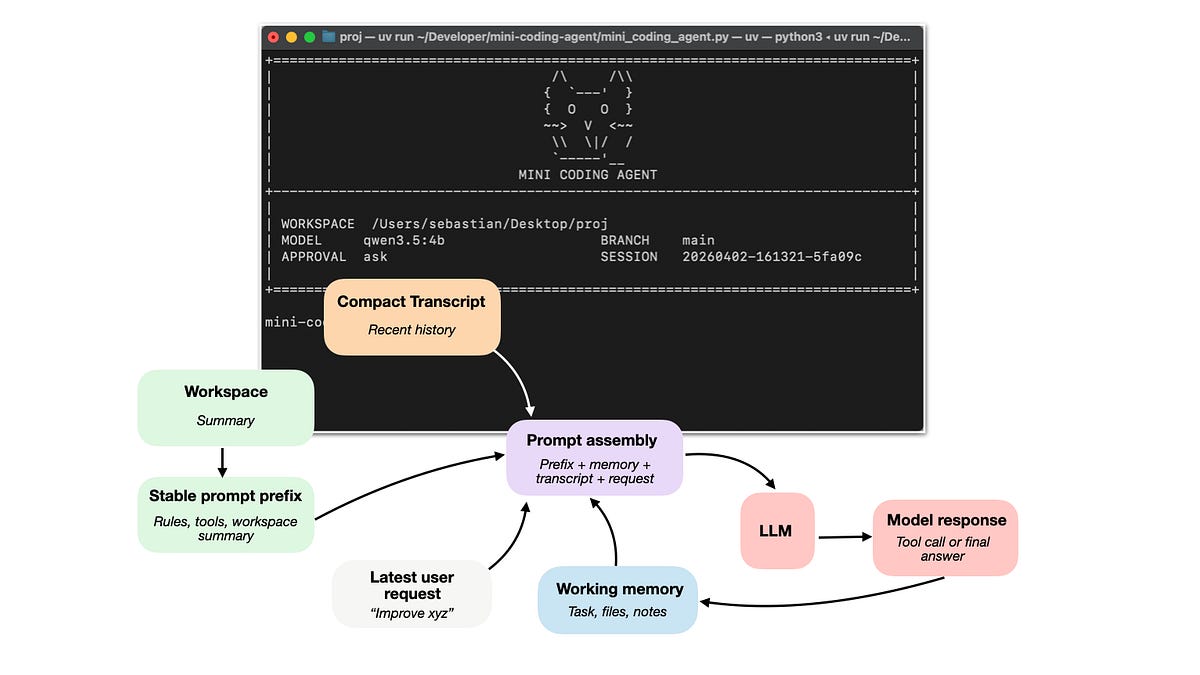
Summary & Key Takeaways
- The article explores the fundamental components that enable AI coding agents to function effectively.
- It highlights the crucial role of "tools," which allow LLMs to interact with external systems and execute specific actions beyond text generation.
- "Memory" is discussed as essential for agents to retain context, learn from past interactions, and maintain state across multiple steps.
- The concept of "repository context" is introduced, emphasizing how agents utilize codebase information for more accurate and relevant code generation and modification.
- These components collectively enhance the practical utility of Large Language Models in real-world software development scenarios.
- The integration of these elements helps overcome common limitations of raw LLMs, making agents more robust and capable.
Our Commentary
The rise of coding agents is one of the most fascinating and, frankly, slightly terrifying developments in AI right now. This article's breakdown of tools, memory, and repo context really hits on the core challenges and innovations. We've seen raw LLMs struggle with complex coding tasks, but giving them "hands" (tools) and "brains" (memory, context) fundamentally changes the game. There's something unsettling about agents churning away at 3 am while nobody's watching, but the potential for productivity gains is undeniable. It makes us wonder how quickly these systems will evolve from assistants to autonomous developers. The implications for developer workflows and even the definition of "coding" itself are profound.