Back to Daily Feed 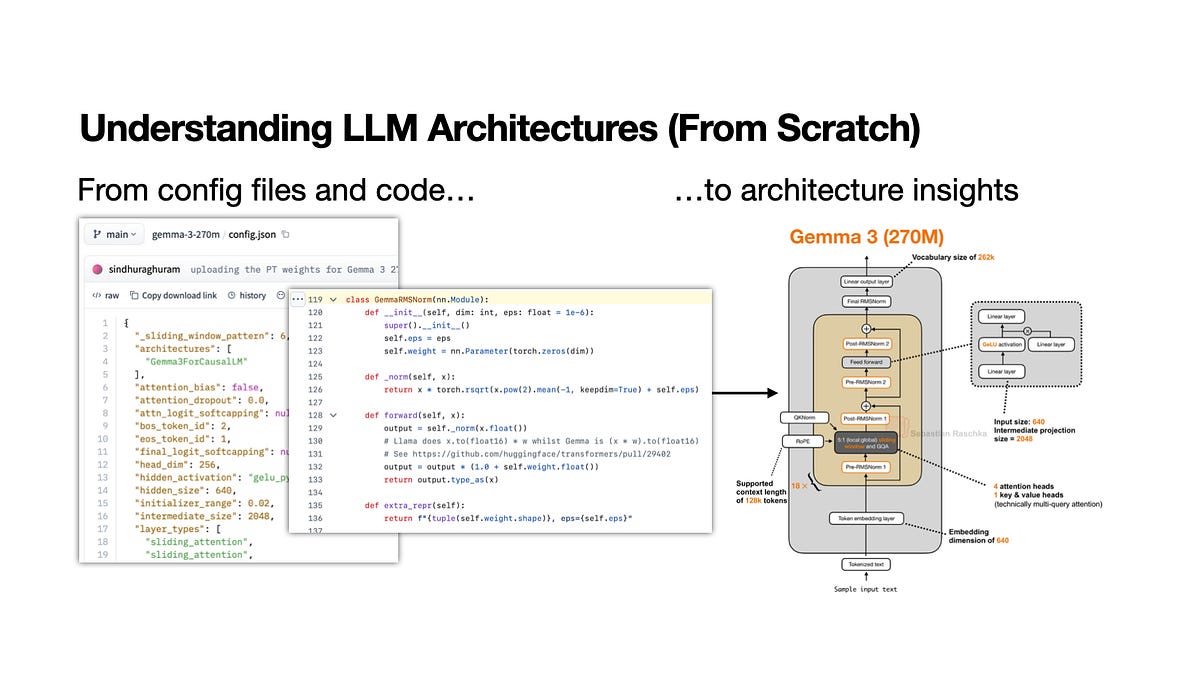
Demystifying LLM Architectures: A Practical Workflow
Worth Reading
Originally published on Ahead of AI by Sebastian Raschka
View Original Article
Share this article:
Summary & Key Takeaways
- Sebastian Raschka presents a five-step workflow for understanding the architectures of new open-weight Large Language Models.
- The process begins with a strategic reading of the research paper, focusing on the abstract, introduction, and conclusion before diving into methods.
- Key components of the model, such as attention mechanisms and tokenizers, are identified and analyzed.
- Understanding the data flow through the model during both inference and training is a crucial step.
- The workflow encourages examining the model's code implementation to bridge theoretical understanding with practical application.
- Finally, hands-on experimentation and visualization are recommended to solidify comprehension and test hypotheses.
Our Commentary
This is exactly the kind of practical, actionable advice we love to see. Understanding LLM architectures can feel like staring into a black box, especially with the rapid pace of new model releases. Raschka's systematic approach provides a much-needed roadmap. We particularly appreciate the emphasis on starting with the paper's high-level overview before getting lost in the weeds, and then cross-referencing with code. It's a reminder that even complex systems can be broken down into manageable, understandable parts. This workflow isn't just for LLMs; it's a solid framework for tackling any complex technical documentation or codebase.
View Original Article
Share this article: