Back to Daily Feed 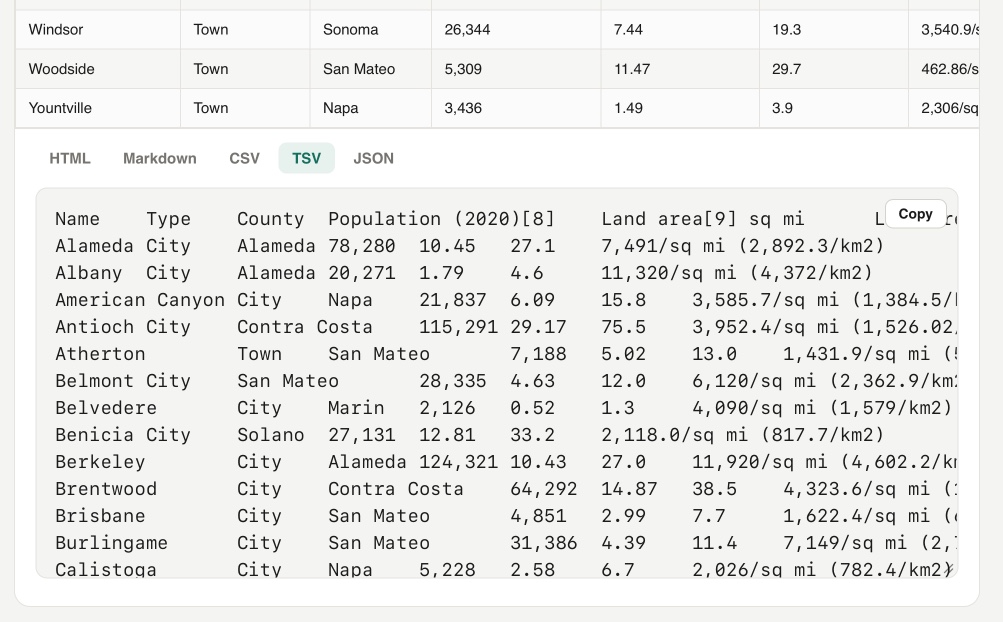
HTML Table Extractor: Convert Rich Text Tables to Multiple Formats
Worth Reading
Originally published on Simon Willison's Weblog by Simon Willison
View Original Article
Share this article:
Summary & Key Takeaways
- Introduces a new web tool for extracting HTML tables from rich text.
- Supports conversion to HTML, Markdown, CSV, TSV, and JSON formats.
- Designed for easy data extraction from browser-pasted content.
- Features integration with Wikipedia's CORS API for direct page content import.
- Builds on previous work, like the Rich text to Markdown tool.
- Aims to simplify data handling from web pages.
Our Commentary
Simon Willison just dropped another one of his incredibly useful, hyper-focused tools. We're always impressed by how he spots these little friction points in web workflows and just... builds a solution. This HTML table extractor is exactly that – a simple, effective answer to a common data-wrangling headache. The Wikipedia CORS API integration is a particularly clever touch; it's the kind of practical, no-fuss feature that makes a tool genuinely indispensable for certain tasks. I mean, who hasn't wrestled with copying tables from a webpage? This just makes it work.
View Original Article
Share this article: